2 Datensatz
In einer Erhebung wurde von N = 200 Personen der “Lernaufwand” in Stunden, die Anwesenheit in den relevanten LVs (“Anwesenheit_LVs” in Prozent), die Einschätzung der “Wichtigkeit” des entsprechenden Faches (1 = unwichtig, 10 = wichtig) und die Anwesenheit zu den Tutoriumseinheiten (“Anwesenheit_Tut”) erhoben. Das “Ergebnis” jeder Person liegt als erreichte Prozentpunkte bei der Klausur vor. Des weiteren sind noch die Probandennumer (“PNr”) und das “Geschlecht” (0 = M, 1 = W) gegeben.
| PNr | Geschlecht | Ergebnis | Lernaufwand | Anwesenheit_LVs | Anwesenheit_Tut | Wichtigkeit |
|---|---|---|---|---|---|---|
| 1 | M | 16.67 | 0.507 | 44.44 | 7.72 | 1 |
| 2 | M | 19.44 | 7.864 | 31.75 | 7.14 | 1 |
| 3 | F | 19.44 | 2.984 | 30.16 | 6.79 | 1 |
| 4 | F | 19.44 | 10.191 | 31.75 | 6.89 | 2 |
| 5 | F | 8.33 | 8.463 | 14.29 | 3.94 | 3 |
| 6 | M | 16.67 | 5.609 | 31.75 | 5.76 | 4 |
| 7 | F | 19.44 | 4.282 | 1.59 | 3.90 | 4 |
| 8 | F | 25.00 | 3.948 | 30.16 | 8.32 | 4 |
| 9 | M | 52.78 | 6.765 | 19.05 | 5.75 | 4 |
| 10 | F | 19.44 | 12.082 | 12.70 | 5.02 | 5 |
2.2 Modellberechnung
2.2.1 Modell 1
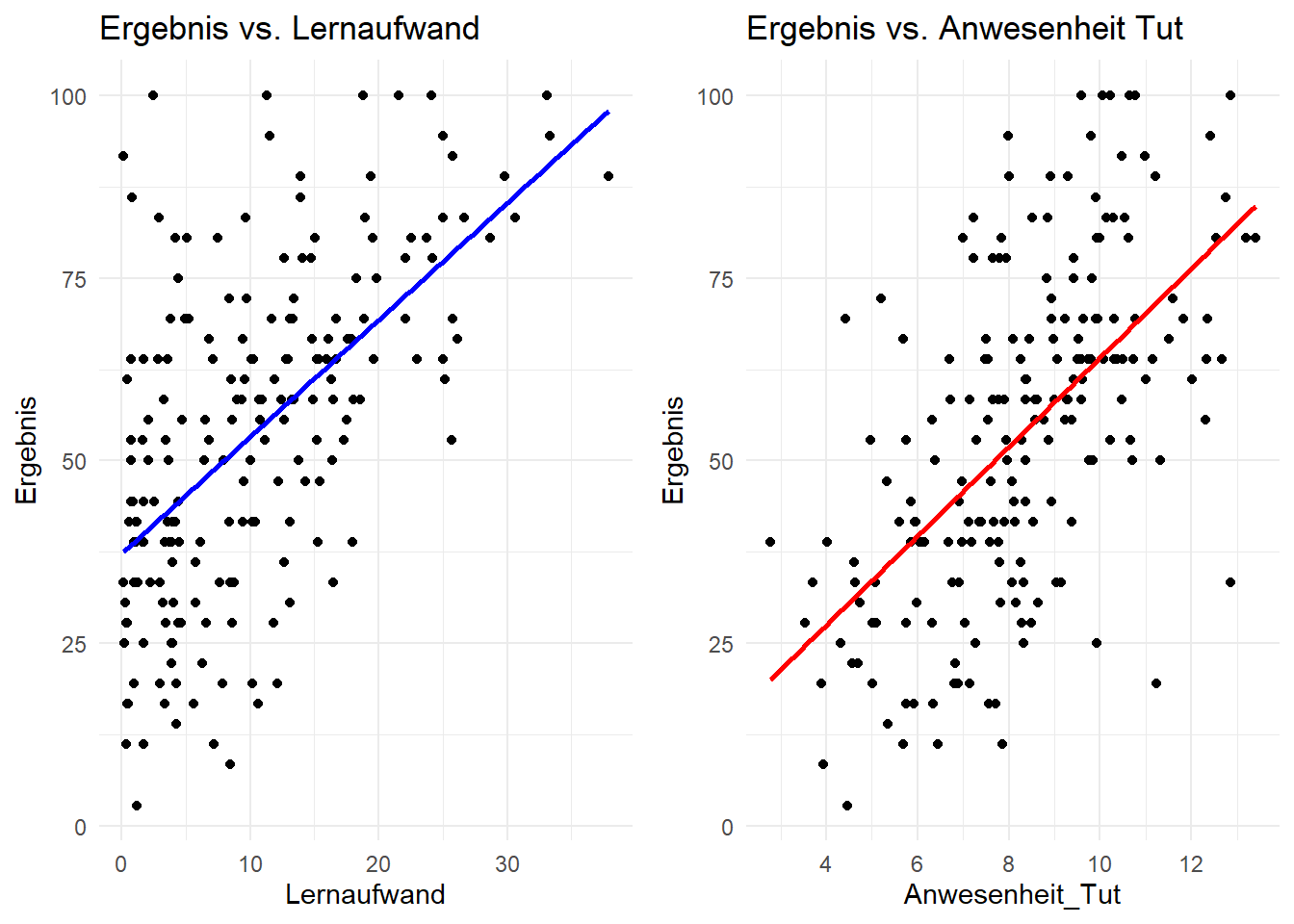
Nachfolgend die Ergebnisse der einfachen linearen Regression des Modells:
Aufruf in R:
Ergebnistabellen:
| R_SE | R2 | AdjR2 | FVal | df1 | df2 | N | pVal | |
|---|---|---|---|---|---|---|---|---|
| value | 18.3 | 0.335 | 0.331 | 99.6 | 1 | 198 | 200 | 0 |
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 37.3 | 2.093 | 17.80 | 0 |
| Lernaufwand | 1.6 | 0.161 | 9.98 | 0 |
| Min | 1Q.25% | Median | 3Q.75% | Max |
|---|---|---|---|---|
| -42.5 | -12.2 | -0.109 | 10.3 | 58.9 |
2.2.2 Modell 2
Nachfolgend die Ergebnisse der einfachen linearen Regression des Modells:
Aufruf in R:
Ergebnistabellen:
| R_SE | R2 | AdjR2 | FVal | df1 | df2 | N | pVal | |
|---|---|---|---|---|---|---|---|---|
| value | 18.1 | 0.352 | 0.348 | 107 | 1 | 198 | 200 | 0 |
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 3.05 | 5.050 | 0.603 | 0.547 |
| Anwesenheit_Tut | 6.11 | 0.589 | 10.362 | 0.000 |
| Min | 1Q.25% | Median | 3Q.75% | Max |
|---|---|---|---|---|
| -52.3 | -11.2 | -0.941 | 11.9 | 42.6 |
2.2.3 Modell 3
Nachfolgend die Ergebnisse der einfachen linearen Regression des Modells:
Aufruf in R:
Ergebnistabellen:
| R_SE | R2 | AdjR2 | FVal | df1 | df2 | N | pVal | |
|---|---|---|---|---|---|---|---|---|
| value | 14.1 | 0.608 | 0.604 | 153 | 2 | 197 | 200 | 0 |
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -5.84 | 4.013 | -1.46 | 0.147 |
| Lernaufwand | 1.41 | 0.125 | 11.36 | 0.000 |
| Anwesenheit_Tut | 5.43 | 0.463 | 11.73 | 0.000 |
| Min | 1Q.25% | Median | 3Q.75% | Max |
|---|---|---|---|---|
| -37.1 | -9.86 | 0.982 | 8.44 | 50.3 |
2.2.4 Standardisierte Koeffizienten
Bei den Ergebnissen im Modell 3 werden die Koeffizienten zwar auf statistische Signifikanz geprüft werden, aber eine Vergleichbarkeit zwischen der Gewichtung eines Koeffizienten zu den anderen im Modell befindlichen Koeffizienten ist nicht gegeben.
Um das zu erreichen, muss man einfach nur die standardisierten Koeffizienten berechnen. Nachfolgende Tabelle zeigt die standardisierten Werte für den jeweiligen Paramater:
| Parameter | Std_Coefficient | CI | CI_low | CI_high |
|---|---|---|---|---|
| (Intercept) | 0.000 | 0.95 | -0.088 | 0.088 |
| Lernaufwand | 0.511 | 0.95 | 0.422 | 0.599 |
| Anwesenheit_Tut | 0.527 | 0.95 | 0.439 | 0.616 |
Die Ergebnisse lassen nun den Vergleich der beiden verwendeten Prädiktoren über die standardisierten Koeffizienten zu.